
This is a rough outline of my verbal remarks while giving a presentation at the Software Industry Conference. Regular readers of my blog will notice it has a lot of overlap with previous posts on the topic, but I thought posting it would save presentation watchers from having to take copious notes on URLs and expand the reach of the presentation to people who couldn’t attend this year.
Brief Biography
My name is Patrick McKenzie. For the last six years I was working in Japan, primarily as a software engineer. In the interim, I started a small software company in my spare time, at about five hours a week, which recently allowed me to quit my day job. Roughly half my sales and three quarters of my profits come as a result of organic SEO, and the majority of the remainder come from AdWords. If you need to know about AdWords, talk to Dave Collins, who is also attending. This presentation is about fairly advanced tactics — if you need beginner-friendly SEO advice, I recommend reading SEOMoz’s blog or taking a look at SEOBook.
Bingo Card Creator makes bingo cards for elementary schoolteachers. This lets them, for example, teach a unit on chemistry and then, as a fun review game, call out the names of compounds like “ozone” and have students search out the chemical symbols on their bingo cards. Students enjoy the game because it is more fun than drilling. Teachers enjoy the game because it scales to any number of students and slides easily into the schedule. However, making the cards by hand is a bit of a pain, so they go searching on the Internet for cards which already exist and find my website. I try to sell them a program which automates card creation.
SEO can be a powerful tool for finding more prospects for your business and increasing sales.
SEO In A Nutshell
People treat SEO like it is black magic, but at the core it is very simple: Content + Links = You Win.
Content: Fundamentally, users searching are looking for keywords, and Google wants to send searchers to content which is responsive to the intent of the searcher. Overwhelmingly, this means to content directly responsive to the keywords. This is particularly true on the long tail, meaning queries which are not near the top of the query frequency distribution. Many more people search for “credit cards” than for “How do I make a blueberry pie?”
For the most popular queries, the page that ranks will likely not be laser-targeted on “credit cards”. However, for the long tail, a page that is laser-targeted will tend to win if it exists. The reason is that Google thinks that your wording carries subtle clues of your intent, so it should generally be respected. Someone looking for “How to make a blueberry pie?” isn’t necessarily as sophisticated a cook as someone who searches for “blueberry pie recipe” — they might not even be looking with the intention of making a blueberry pie, but rather out of curiosity as to how it is made, and so a recipe does not directly answer their intent.
Links: With billions of pages on the Internet, there needs to be a way to sift the wheat from the chaff and determine who wins out of multiple close pages. The strongest signal for this is how trusted a site and how trusted a page is, and this is overwhelmingly measured by links. A link from a trusted page to another page says “I trust this other page”, and the aggregate graph shows you which pages are most trusted on the Internet. Note that trust is used as a proxy for quality because it is almost impossible to measure quality directly.
It is important to mention that links to one bit of content on your site help all other content — perhaps not as much as the linked content, but still substantially. Wikipedia’s article on dolphins doesn’t necessarily have thousands of links pointing to it, but over their millions of articles like the History of the Ottoman empire, they have accumulated trust sufficient that a new page on wiki is assumed to be much better than a new page on a hobbyist’s blog. Note that because Wiki ranks for nearly everything they tend to accumulate new citations when people are looking for someone to cite. This causes a virtuous cycle (for Wiki, anyway): winners win. You’ll see this over and over in SEO.
Despite this equation looking additive, SEO very rarely shows linear benefits. Benefits compound multiplicatively or exponentially. Sadly, many companies try to develop their SEO in a linear fashion: writing all content by hand, searching out links one at a time, etc. We’ll present a few techniques to do it more efficiently.
The Biggest Single Problem
The biggest single problem with software company’s SEO is that they treat their website like a second class citizen. The product gets total focus from a team of talented engineers for a year, and then the website is whipped up at 2 AM in the morning on release day and never touched again. You have to treat your website like it was a shipping software product of your company.
It needs:
- testing
- design
- strategic thought into feature set
- continuous improvement
- for loops
“For loops?” Yes, for loops. You’d never do calculations by counting on your fingers when you have a computer available to do them for you. Hand-writing all content in Notepad is essentially the same. Content should be separated from presentation — via templates & etc — so that you can reuse both the content and presentational elements. Code reuse: not just for software.
Scalable Content Generation
Does anyone have a thought about how large a website’s optimal size should be? 10 pages? A hundred pages? No, in the current environment, the best size for a website is “as large as it possibly can be”, because of how this helps you exploit the long tail. As long as you have a well-designed site architecture and sufficient trust, every marginal topic you cover on your website generates marginal traffic. And if you can outsource or automate this such that the marginal cost of creating a piece of content is less than the marginal revenue received from it, it makes sense to blow your website up.
This is especially powerful if you can make creation of content purely a “Pay money and it happens” endeavor, which lets you treat SEO like a channel like PPC: pour in money, watch sales, laugh all the way to the bank. The difference is that you get to keep your SEO gains forever rather than having to rebuy them on every click like PPC. This is extraordinarily powerful if you do it right. Here’s how:
Use a CMS
The first thing you need to enable scalable content generation is a CMS. People need to be able to create additional content for the website without hand-editing it. WordPress is an excellent first choice, but you can get very, very creative with custom CMSes for content types which are specific to your business if you have web development expertise.
Note that “content” isn’t necessarily just blog posts. It is anything your customers perceive value out of, anything which solves problems for them. That could be digitizing your documentation, or answering common questions in your niche (“How do I…” is a very common query pattern), or taking large complex data sets and explaining their elements individually in a comprehensible fashion. Also note that it isn’t strictly text: you can do images and even video in a scalable fashion these days.
For example, using Flickr Creative Commons search, you can tap millions of talented photographers for free to get photos, so illustrating thousands of pages is as simple as searching, copying, and crediting the photographer. You can use GraphicsMagick or ImageMagick to create or annotate images algorithmically. You can use graphing libraries to create beautiful graphs from boring CSV files — more on that later.
The reasons why you’d use a CMS are they make content easy to create and edit, so you’ll do more of it. Additionally, by eliminating the dependency on the webmaster, you can have non-technical employees or freelancers create content for you. This is key to achieving scale. You can also automate on-page SEO optimization — proper title tags, interlinking, etc — so that content creators don’t have to worry about this themselves.
Outsource Writing
You are expensive. English majors are cheap. Especially in the current down economy, stay at home moms, young graduates, the recently unemployed, and many other very talented folks are willing to write for cheap, particularly from home. This lets you push the marginal cost of creating a new page to $10 ~ $15 or lower. As long as you can monetize that page at a multiple of that, you’ll do very well for yourself. Demand Media is absolutely killing it with this model.
Finding and managing writers is difficult. If you use freelancers and find good ones, hold onto them for dear life, since training and management are your main costs. Standardize instructions to freelancers and find folks who you can rely on to exercise independent thinking.
You can also get content created as a service, using TextBroker. Think of the content on your website as a pyramid: you have a few pages handwritten by domain experts with quality off the chart, and then a base of the pyramid which is acceptable but perhaps not awe-inspiring. At the 4 star quality level, you can get content in virtually infinite quantity at 2.2 cents per word. You can either have someone copy/paste this into your website or do a bit of work with their API and automate the whole process.
You can use software to increase the quality of outsourced content. For example, putting a picture on it automatically makes it better. You can automate that process so your editors can quickly do it for all pages. You can remix common page elements — calls to action, etc — which are polished to a mirror shine with the outsourced content. You can also mix content from multiple sources to multiply its effectiveness: if you have 3 user segments and 3 features they really value, that might be 9 pages. (If you use 2 features per page, that is 18. As you can see, the math is gets very compelling very quickly.)
Milk It
Now that you’re set up to do content at scale, you can focus on doing it well. The best content is:
Modular: You can use it in multiple places on the website. You paid good money for it. If you can use it in two places, the cost just declined by half.
Evergreen: The best possible value for an expiration date is “never”. Chasing the news means your content gets stale and stops providing value for the business. Answering the common, recurring, eternal problems and aspirations of your market segment means content written this year will never go out of style. That lets you treat content as durable capital. Also, because it tends to pick up links over time, it will get increasing traffic over time.
The first piece of content I made for my website took me two hours to write. It made $100 the first month. Not bad, but why only get paid once? It has gone on to make me thousands over the years, and it will never go out of style.
Competitively Defensible: One of the tough things about blog posts is that any idiot can get a blog up as easily as you can. Ideally, you want to focus on content which other people can’t conveniently duplicate. OKCupid’s blog posts about dating data are a superb example of this: they use data that only they have, and they’ve made themselves synonymous with the category. No wonder they’re in the top 3 for “online dating”. Proprietary data, technical processes which are hard to duplicate, and other similar barriers establish a moat around your SEO advantage.
Process-oriented: If something works, you want to be able to exploit it in a repeatable fashion. Novelty is an excellent motivational factor and you can’t lose it, but novelty that can be repeated is a wonderful thing to have. You also want to have a defined step where you see what worked and what didn’t, so that you can improve your efforts as you go on.
Tracking:
Track what works! Do more of that! Install Google Analytics or similar to see what keywords people are reaching for on your site. Keywords (or AdWords data) are great sources of future improvements. Track conversions based on landing page, and create more content based on the content which is really winning. If content should be winning but isn’t, figure out why for later iterations — maybe it needs more external or internal promotion, a different slant, a different target market, etc.
Case Study
Getting into the heads of my teachers for a moment — a key step — most teachers have a lesson planned out and need an activity to slot into it. For example, they know they have a lesson about the American Revolution coming up. Some of them, who already like bingo, are going to look for American Revolution bingo cards. If my site ranked for that, that would be an opportunity to tell them that they could use software to create not just American Revolution activities but bingo for any lesson if they just bought my software.
So I made a CMS which, given a list of words and some explanatory text, would create a downloadable set of 8 bingo cards (great for parents, less great for teachers) on that topic, make a page to pitch that download in, and put an ad for Bingo Card Creator on the page. Note how I’m using this content to upsell the user into more of a relationship with me: signing up for a trial, giving me their email address, maybe eventually buying the software.
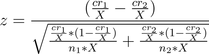
I have a teacher in New Mexico who produces the words and descriptions for me. The pages end up looking like this for the American Revolution. She produces 30 activities a month for $100, and I approve them and they go live instantly. This has been going on for a few years. In the last year, I’ve started doing end-to-end conversion tracking, so I can attribute sales directly to the initial activity people started with.
This really works. Some of the activities, like Summer bingo cards or Baby Shower Bingo cards, have resulted in thousands of dollars in sales in the last year. $3.50 in investment, thousands in returns. And there is a long tail of results:

This graph shows the 132 of the 900 activities which generated a sale in the last year. You can see that there is a long tail which each generated one sale — in fact, a hundred of them. Sure, you might not think that Famous Volcano bingo cards would be that popular, but I’ll pay $3.50 to get a $30 sale as often as the opportunity is offered. These will also continue producing value in the next years, as they already have over the last several years: note that roughly half of these which produced a sale in the last 12 months were written in 2007 or 2008.
This took only a week or two to code up, and now 5 minutes a month sending my check and a thank-you note to the freelancer. I’ve paid her about $3,000 over the last few years to write content. In the last year alone, it has generated well over $20,000 in sales. If you do things this efficiently, SEO becomes a channel like PPC — put in a quarter, get out a dollar, redeploy the profits to increase growth.
Any software company can create content like this, with a bit of strategic thinking, some engineering deployed, and outsourced content creation. Try it — you can do an experiment for just a few hundred dollars. If it works, invest more. (Aaron Wall says that one of the big problems is that people do not exploit things that work. If you’ve got it, flaunt it — until it stops working.)
Linkbait
Linkbait is creating content intended to solicit links to your website. This can be by exploiting the psychology of users — they show things to friends because they agree with them strongly, or they hate them. They create links because it creates value for them, not value for you — it increases their social status, it flatters their view of the world, it solves their problems.
All people are not equal on the Internet: twenty-something technologists in San Fransisco create hundreds of times more links per year than retired teachers in Florida. All else being equal, it makes sense to create more of your linkbait targeted at heavy linking groups. They’ve been labeled the Linkerati by SEOMoz, and I recommend the entire series of posts on them highly.
Software developers have some unique, effective ways to create linkbait. For example:
Open Source Software
OSS developers and users are generally in very link-rich demographics. OSS which solves problems for businesses tends to pick up links from, e.g., consultants deploying it — they will cite your website to justify their billing rate. That is a huge win for you. There are also numerous blogs which cover practically everything which happens in OSS.
OSS is fairly difficult to duplicate as linkbait, because software development is hard. (Don’t worry about people copying it — you’ll be the canonical source, and the canonical source for OSS tends to win the citation link. Make sure that is on your site rather than on Github, etc.)
OSS in new fields in software — for example, Rails development the last few years — has landgrab economics. The first semi-decent OSS in a particular category tends to win a lot of the links and mindshare. So get cracking! And keep your eyes open for new opportunities, particularly for bits of infrastructural code which you were going to write for your business needs anyhow.
Case Study: A/Bingo
I’m extraordinarily interested in A/B testing, and wanted to do more of it on my site. At the time, there was no good A/B testing option for Rails developers. So I wrote one. It went on to become one of the major options for A/B testing in Rails, and was covered on the official Rails blog, Ajaxian, and many other fairly authoritative places on the Internet. It is probably the most effective source of links per unit effort I’ve ever had.
Some tactical notes:
- Put it on your website. You did the work, get the credit for it.
- Invest in a logo — you can get them done very cheaply at 99designs. Pretty things are trusted more.
- Spend time “selling” the OSS software. Documentation, presentation of benefits, etc.
- OSS doesn’t have to be a huge project like Apache. You can do projects in 1 day or 1 week which people will happily use. (Remember, pick things which solve problems.)
Conclusion
I’m always willing to speak to people about this. Feel free to email me (patrick@ this domain).
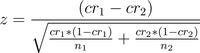

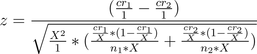
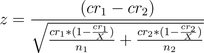
Recent Comments